Технологии
Cassandra
Как использовать Cassandra для решения широкого круга задач по System Design
Базы данных являются фундаментальным и ключевым аспектом проектирования систем, и одной из наиболее универсальных и популярных баз данных, которую полезно иметь в своем арсенале, является Cassandra. Cassandra используется множеством компаний для быстрого масштабирования хранения данных, пропускной способности и скорости чтения. От Discord (рассмотрим далее) до Netflix, Apple и Bloomberg, Cassandra представляет собой NoSQL базу данных, которая прочно укрепилась на рынке и используется для большого спектра задач.
Apache Cassandra - это распределенная NoSQL база данных с открытым исходным кодом. Она реализует модель распределенного хранения семейства столбцов (partitioned wide-column storage model) с семантикой согласованности в конечном счете (eventual consistency). Cassandra работает в кластере и может горизонтально масштабироваться на стандартном оборудовании. Она объединяет элементы архитектуры Dynamo и Bigtable для обработки огромных объемов данных, запросов и гибких требований к хранению.
В данной статье мы рассмотрим возможности Cassandra, которые делают ее привлекательной базой данных, особенно в контексте проектирования систем. Мы обсудим наиболее важные внутренние механизмы Cassandra, чтобы раскрыть принципы ее работы. Наконец, мы поговорим о задачах и методах использования Cassandra. Вперед!
Основы Cassandra
Модель данных
Cassandra имеет ряд базовых понятий, которые определяют, как вы храните и взаимодействуете с данными.
- Пространство ключей (keyspace) - высший организационный уровень в Cassandra, эквивалент базы данных в реляционных системах вроде PostgreSQL или MySQL. Пространство ключей определяет стратегии репликации (обсуждаются позже) для управления избыточностью и доступностью данных. Оно также содержит пользовательские типы данных (UDT - user-defined types), которые вы можете создать.
- Таблица (table) - находится внутри пространства ключей и организует данные в строки. Каждая таблица имеет схему, определяющую ее столбцы и структуру первичного ключа.
- Строка (row) - отдельная запись в таблице, идентифицируемая первичным ключом. Каждая строка хранит значения по нескольким столбцам.
- Столбец (column) - фактическая единица хранения данных. Столбец имеет название, тип и значение для конкретной строки. Не обязательно указывать все столбцы для каждой строки в таблице Cassandra. Cassandra является базой данных с семейством столбцов (wide-column database), поэтому указанные столбцы могут различаться для разных строк таблицы, делая Cassandra более гибкой, чем реляционная база данных, которая требует записи для каждого столбца в строке (даже если эта запись равна NULL). Кроме того, каждый столбец ассоциируется с временной отметкой, обозначающей время его записи. Когда возникает конфликт записи в столбце между репликами, он решается путем правила "последняя запись побеждает" (last write wins).
На самом базовом уровне структуры данных Cassandra можно сравнить с большим файлом JSON.
{
"keyspace1": {
"table1": {
"row1": {
"col1": 1,
"col2": "2"
},
"row2": {
"col1": 10,
"col3": 3.0
},
"row3": {
"col4": {
"company": "Now Interview",
"city": "Moscow",
"rating": "Super Great"
}
}
}
}
}Cтолбцы Cassandra поддерживают множество типов данных, включая пользовательские типы и JSON-значения. Это делает Cassandra очень гибкой в качестве хранилища данных как для плоских, так и для вложенных структур.
Первичный ключ
Одной из важнейших структур в Cassandra является "первичный ключ". Каждая строка в таблице уникально представлена именно первичным ключом. Первичный ключ состоит из одного или нескольких ключей партиционирования (partition key) и может включать кластерные ключи (clustering keys). Рассмотрим эти термины подробнее.
- Ключ партиционирования - один или несколько столбцов, которые определяют, в каком разделе (partition) находится строка. Именно по этим ключам происходит разбиение данных на разделы.
- Кластерный ключ - ноль или более столбцов, которые определяют порядок сортировки строк внутри раздела. Такой порядок важен для эффективного доступа к данным в зависимости от модели данных, и Cassandra предоставляет пользователю возможность контролировать его через кластерные ключи.
При создании таблицы в Cassandra через CQL (Cassandra Query Language) первичный ключ указывается как часть схемы таблицы. Ниже приведены несколько примеров различных первичных ключей с комментариями:
-- Первичный ключ с ключом партиционирования a, без кластерных ключей
CREATE TABLE t (a text, b text, c text, PRIMARY KEY (a));
-- Первичный ключ с ключом партиционирования a, кластерный ключ b по возрастанию
CREATE TABLE t (a text, b text, c text PRIMARY KEY ((a), b))
WITH CLUSTERING ORDER BY (b ASC);
-- Первичный ключ с составным ключом партиционирования a + b, кластерный ключ c
CREATE TABLE t (a text, b text, c text, d text, PRIMARY KEY ((a, b), c));
-- Первичный ключ с ключом партиционирования a, кластерные ключи b + c
CREATE TABLE t (a text, b text, c text, d text, PRIMARY KEY ((a), b, c));
-- Первичный ключ с ключом партиционирования a, кластерные ключи b + c (альтернативный синтаксис)
CREATE TABLE t (a text, b text, c text, d text, PRIMARY KEY (a, b, c));Концепция первичного ключа и его составных частей может напомнить определение первичного ключа в DynamoDB. Эта концепция практически полностью совпадает между двумя базами данных.
Основные концепции
При использовании Cassandra на System Design важно понимать некоторые детали ее устройства. Вы должны уметь объяснить принцип работы, особенно если интервьюер задает конкретные вопросы, или же углублиться в подробности хранения данных, масштабируемость, эффективность запросов и прочие аспекты, которые могут иметь значительное влияние на проектирование вашей архитектуры. В данном разделе мы рассмотрим ключевые особенности Cassandra, чтобы дать вам необходимую теоретическую базу.
Разбиение на разделы (Partitioning)
Одним из наиболее фундаментальных аспектов Cassandra является схема разбиения данных. Методы разбиения, используемые в Cassandra, чрезвычайно надежны и заслуживают отдельного изучения в рамках System Design, поскольку их принципы можно применять и в других областях ваших проектов (например, кэширование, балансировка нагрузки и др.).
Cassandra горизонтально масштабируется путем распределения данных по множеству узлов кластера. Для успешного разделения данных Cassandra использует согласованное хеширование (consistent hashing). Согласованное хеширование является базовой техникой, применяемой в распределенных системах для равномерного распределения данных / нагрузки по машинам таким образом, чтобы минимизировать переносы данных при добавлении или удалении узлов в кластер.
В традиционной схеме выбирается некоторое количество узлов, и целевой узел
определяется как: hash(value) % num_nodes. Это распределяет данные по узлам,
но есть две проблемы:
-
Если изменяется количество узлов (добавляется или удаляется узел), то многие значения будут назначены новым узлам. В распределенной системе вроде базы данных это означало бы чрезмерное перемещение данных между узлами.
-
Кроме того, если вам не повезет с выбранной схемой хеширования, большое количество значений может оказаться на одном узле, что приведет к неравномерному распределению нагрузки между узлами.
Согласованное хеширование использует улучшенный подход.
Вместо того, чтобы вычислять хеш-значение и применять операцию деления по модулю для выбора узла, согласованное хеширование преобразует значение в диапазон целых чисел, располагаемых на кольце. Каждое значение на этом кольце соответствует определенному узлу. Когда значение хешируется, оно преобразуется в целое число. Затем кольцо обходится по часовой стрелке, пока не будет найдено первое значение, соответствующее узлу. Значение сохраняется именно на этом узле.
Этот подход предотвращает избыточный перенос данных при добавлении или удалении узла, поскольку затрагивается лишь один соседний узел. Если узел добавляется в систему, то на него переносятся некоторые данные с предыдущего узла. Если узел удаляется, то данные с этого узла переназначаются следующему узлу по часовой стрелке.
Однако это еще не решает проблему неравномерной нагрузки между узлами. Поэтому Cassandra кроме этого еще использует понятие виртуальных узлов (vnodes). На кольце располагаются виртуальные узлы (vnodes) и каждый такой виртуальный узел связан с физическим узлом. Это позволяет равномерно распределять нагрузку по кластеру.
Такая схема также дает возможность эффективно использовать ресурсы разных физических узлов; некоторые физические узлы могут представлять собой большие машины с большими ресурсами, поэтому они могут отвечать за большее количество виртуальных узлов. Ниже показано, как может выглядеть кластер, где значения, называемые токенами (t1, t2 и т.д.), представлены на кольце, виртуальные узлы сопоставлены этим токенам, а разные физические узлы обозначены цветами виртуальных узлов.
Подробнее о согласованном хешировании можно узнать в нашей статье.
Репликация
В Cassandra данные реплицируются на узлы кластера вдоль кольца хеширования, обеспечивая чрезвычайно высокую доступность. Пространства ключей задают нужную конфигурацию репликации данных.
Cassandra выбирает узлы для репликации данных путем обхода по часовой стрелке от виртуального узла (vnode), который соответствует хешированному значению. Например, если Cassandra пытается реплицировать данные на три узла, она сначала вычисляет хеш-значение для определенного узла, а затем последовательно проходит по кольцу по часовой стрелке, выбирая два дополнительных узла (vnode) в качестве реплик. Если Cassandra обнаруживает виртуальные узлы, размещенные на одном физическом узле с уже выбранными репликами, она пропускает их. Это нужно, чтобы избежать ситуации, когда потеря одного физического узла приводит к одновременному выходу из строя сразу нескольких реплик.
Cassandra поддерживает две разные стратегии репликации: NetworkTopologyStrategy и SimpleStrategy.
-
NetworkTopologyStrategy: Эта стратегия рекомендуется для производственных сред и учитывает структуру дата центров. Она позволяет хранить копии данных в разных дата центрах, чтобы обеспечить отказоустойчивость в случае сбоя. Дополнительно эта стратегия распределяет реплики по разным стойкам внутри дата центра. Это уменьшает риск потери всех данных при выходе из строя одной стойки.
-
SimpleStrategy: Это простая стратегия, определяющая размещение реплик путем последовательного выбора узлов по часовой стрелке (описанный ранее метод). Она подходит для простых развертываний и тестирования.
Ниже приведен пример синтаксиса CQL (Cassandra Query Language) для задания конфигураций различных стратегий репликации пространства ключей:
-- 3 реплики
ALTER KEYSPACE chat
WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 3 };
-- 3 реплики в дата центре 1 и 2 реплики в дата центре 2
ALTER KEYSPACE chat
WITH REPLICATION = {'class': 'NetworkTopologyStrategy', 'dc1': 3, 'dc2': 2};Согласованность
Как и любая распределенная система, Cassandra соотносится с теоремой CAP. Cassandra предоставляет пользователям гибкость в настройках операций чтения и записи, что позволяет находить компромисс между согласованностью и доступностью. Поскольку проектирование каждой системы включает определенный уровень анализа и компромисса согласно теореме CAP, важно понимать доступные вам рычаги управления в Cassandra.
Cassandra не поддерживает транзакций и не обеспечивает гарантий ACID. Она поддерживает лишь атомарные и изолированные операции записи на уровне строк внутри раздела, и на этом все. Подробнее об этом можно почитать здесь.
Cassandra дает возможность выбрать один из уровней согласованности (consistency
levels) для операций чтения и записи. Эти уровни определяют количество узлов,
которое должно подтвердить успешность операции записи или чтения. Различные
комбинации обеспечивают различное поведение в плане согласованности и
доступности. Диапазон уровней варьируется от уровня ONE, при котором
достаточно подтверждения от одной реплики, до уровня ALL, при котором
подтверждение требуется от всех реплик. Подробнее об уровнях согласованности
можно узнать
здесь.
Один важный уровень согласованности, который стоит рассмотреть, называется
QUORUM. Уровень QUORUM требует подтверждения большинства реплик (n/2 + 1).
Применение уровня QUORUM одновременно для операций записи и чтения гарантирует
видимость записей при чтении, поскольку хотя бы один общий узел гарантированно
участвует как в операции записи, так и в операции чтения. Для иллюстрации
рассмотрим группу из трех узлов. Согласно формуле 3/2 + 1 = 2, значит, для
успешной записи и последующего успешного чтения необходима запись и чтение
минимум двух из трех узлов. Это означает, что запись всегда будет доступна при
последующем чтении, потому что хотя бы один узел из тех двух обязательно видел
запись.
Обычно Cassandra стремится к состоянию "согласованности в конечном счете" для всех уровней согласованности, при котором все реплики содержат самые свежие данные при условии, что прошло достаточно времени.
Маршрутизация запросов
Любой узел Cassandra способен обслуживать запросы, поскольку каждый узел в кластере может выступать в роли "координатора запросов" (query coordinator). Узлы в Cassandra знают друг о друге и состоянии остальных живых узлов в кластере. Они обмениваются информацией о кластере посредством протокола gossip, который мы обсудим позже. Узлы также способны определить местоположение данных в кластере используя согласованное хэширование и знание стратегии репликации / уровня согласованности. Когда клиент отправляет запрос, он выбирает узел, который становится координатором, и этот координатор далее направляет запросы узлам, хранящим данные (последовательности реплик).
Модель хранения данных
Понимание модели хранения Cassandra важно, потому что именно она является одной из ключевых сильных сторон системы и обеспечивает высокую пропускную способность записи. Cassandra использует структуру данных, называемую LSM деревом (Log Structured Merge Tree). LSM дерево используется вместо B-дерева, которое является предпочтительным выбором для большинства баз данных (реляционные БД, DynamoDB).
Прежде чем углубляться в детали, важно пояснить, как Cassandra обрабатывает операции записи по сравнению с другими базами данных. Cassandra ориентирована на скорость записи, а не чтения. Каждая операция создания, обновления или удаления представляет собой новую запись (с некоторыми исключениями). Cassandra использует порядок этих записей для определения состояния строки данных. Например, если строка создана, а затем обновлена позднее, Cassandra определяет состояние строки, рассматривая сначала операцию создания, а затем обновления, а не просто имея финальное состояние этой строки.
То же самое относится и к удалениям, которые можно рассматривать как "удаление через обновление". Cassandra записывает специальную отметку, называемую "tombstone", для операций удаления строк. Благодаря LSM дереву Cassandra эффективно отслеживает состояние строки, одновременно записывая данные в базу практически исключительно методом "добавления" записей ("append on" writes).
Три основных компонента структуры LSM дерева:
- Журнал транзакций (Commit Log) - Это своего рода журнал упреждающей записи, обеспечивающий устойчивость записей для узлов Cassandra.
- Таблица в памяти (Memtable) - Хранит данные записи в памяти. Она отсортирована по первичному ключу каждой строки.
- Файл на диске со строками (SSTable) - Техническое название "Sorted String Table" (таблица сортированных строк) - неизменяемый файл на диске, содержащий данные, сброшенные ранее из Memtable.
Все три компонента работают совместно следующим образом при выполнении записи:
- Запись поступает на узел.
- Эта запись фиксируется в журнале транзакций (Commit Log), чтобы предотвратить потерю данных в случае отказа узла.
- Далее запись сохраняется в памяти в Memtable.
- В конечном итоге, когда достигается определенный порог размера Memtable или проходит определенное время, содержимое Memtable выгружается на диск в виде неизменяемого файла SSTable.
- При выгрузке Memtable соответствующие ей сообщения из журнала транзакций удаляются, освобождая пространство. Теперь, когда Memtable находится на диске в виде неизменяемого SSTable, эти сообщения становятся избыточными.
Приведенная ниже диаграмма иллюстрирует вышеуказанные шаги:
Подводя итог, Memtable хранит недавние записи, объединяя записи для ключей в единую строку, и периодически выгружается на диск в виде неизменяемого SSTable. Журнал транзакций служит журналом упреждающей записи, гарантирующим, что данные не будут потеряны, если они существуют только в Memtable и если узел выходит из строя.
При чтении данных для конкретного ключа Cassandra сначала обращается к Memtable, который содержит самые свежие данные. Если Memtable не имеет данных для указанного ключа, Cassandra использует фильтр Блума (Bloom filter), чтобы определить, какие файлы SSTable на диске могут содержать необходимые данные. Затем Cassandra считывает файлы SSTable последовательно, начиная с самого нового, чтобы найти самую свежую версию данных для указанной строки. Данные в файлах SSTable упорядочены по первичному ключу, что облегчает поиск определенного ключа.
Основываясь на приведенном выше, есть еще два дополнительных понятия, которые необходимо усвоить:
- Уплотнение (Compaction) - чтобы избежать чрезмерного увеличения объема файлов SSTable из-за многочисленных обновлений или удалений строк, Cassandra запускает процесс уплотнения, который объединяет данные в меньший набор файлов SSTable, отражающих консолидированное состояние данных. При этом также удаляются строки, которые были помечены как удаленные, при помощи меток "tombstone". Этот процесс особенно эффективен благодаря тому, что все таблицы отсортированы.
- Индексирование SSTable - Cassandra сохраняет файлы, содержащие смещения в файлах SSTable, что позволяет быстрее извлекать данные с диска. Например, Cassandra может сопоставить ключ 12 смещению 984, что означает, что данные для ключа 12 расположены по этому смещению в файле SSTable. Это немного похоже на то, как B-дерево могло бы указывать на данные на диске.
Протокол Gossip
Узлы Cassandra распространяют информацию по всему кластеру с помощью протокола gossip, представляющего собой схему однорангового взаимодействия для распределения информации между узлами. Универсальное знание о структуре кластера обеспечивает каждому узлу осведомленность обо всех операциях базы данных, устраняет проблему единой точки отказа и позволяет Cassandra быть чрезвычайно надежной базой данных для архитектур, ориентированных на доступность. Как это работает?
Каждый узел отслеживает различную информацию о кластере, такую как какие узлы
активны/доступны, какая схема данных используется и т.п. Узлы управляют номерами
поколений (generation) и версиями (version) каждого известного им узла.
Номер поколения - это временная метка момента загрузки узла. Версия - это
значение логических часов, увеличивающееся примерно каждую секунду. Для всего
кластера эти значения формируют векторные часы (vector
clock).
Эти векторные часы позволяют узлам игнорировать устаревшую информацию о
состоянии кластера.
Узлы регулярно выбирают другие узлы для распространения информации, причем выбор осуществляется вероятностно с уклоном в сторону узлов-источников (seed nodes). Узлы-источники это узлы, которые назначаются Cassandra при старте и настройке кластера и служат гарантированными "горячими точками" (hotspots) для передачи сообщений, обеспечивая связь всех узлов по всему кластеру. Создавая hotspot-ы, Cassandra предотвращает появление суб-кластеров из узлов, возникающих вследствие недостаточной передачи информации по всему кластеру. Cassandra гарантирует, что узлы-источники могут быть всегда найдены через стандартные механизмы обнаружения сервисов.
Отказоустойчивость
В распределенной системе, подобной Cassandra, узлы выходят из строя, и Cassandra должна эффективно выявлять и обрабатывать отказы, чтобы обеспечить эффективное выполнение операций записи и чтения данных. Каким образом Cassandra способна достигать этих требований при масштабировании?
Cassandra применяет технику обнаружения сбоев на основе метода Phi-детектора (Phi Accrual Failure Detector) для выявления отказов во время работы gossip. Каждый узел независимо принимает решение относительно доступности другого узла. Когда узел пытается связаться с другим узлом и тот не отвечает, логика детектирования отказов Cassandra объявляет этот узел "осужденным" (convicted) и прекращает отправлять ему запросы на запись. "Осужденный" узел снова сможет присоединиться к кластеру, когда начнет передавать сигналы heartbeats. Cassandra никогда не сочтет узел окончательно "неработоспособным", пока администратор системы Cassandra не выведет узел из эксплуатации или не выполнит его восстановление. Это делается для того, чтобы предотвратить перебалансировку данных кластера из-за временных сбоев связи / перезапусков узлов.
В ситуациях, когда попытка записи производится на узлы, которые помечены как недоступные, Cassandra задействует метод, называемый "отложенной доставкой" (hinted handoffs). Когда координатор распознает узел как недоступный при попытке записать данные на него, координатор временно сохраняет эти данные, позволяя процессу записи продолжаться. Эта временная информация называется "подсказкой" (hint). Когда недоступный узел вновь определяется как активный, узел (или узлы), владеющие подсказкой, передают эти данные обратно ранее недоступному узлу. Ниже показано, как это выглядит на практике.
Метод "отложенной доставки" главным образом применяется в качестве краткосрочного способа предотвращения потери записей на узлы, находящиеся вне сети. Так как срок жизни подсказок обычно невелик, то любой узел, находящийся вне сети длительное время, либо заменяется на новый, либо подвергается восстановлению администратором кластера.
Как использовать Cassandra
Моделирование данных
При проектировании систем с использованием Cassandra важно правильно моделировать данные, учитывая особенности архитектуры и сильные стороны базы данных.
Если вы пришли из мира реляционных баз данных, моделирование данных в Cassandra поначалу может показаться немного странным. Реляционное моделирование данных сосредоточено на нормализации данных, где каждый экземпляр сущности представлен одной копией, а отношения между сущностями управляются посредством внешних ключей и объединенных таблиц (операций JOIN). Другими словами, моделирование данных для реляционной базы данных основано на отношениях между сущностями (entity-relationship-driven). Однако в Cassandra нет понятия внешних ключей, целостности ссылок, объединений (JOIN) и т.п. Cassandra также не поддерживает нормализацию данных. Вместо этого, моделирование данных в Cassandra основывается на запросах (query-driven).
Эффективность запросов в Cassandra сильно зависит от способа хранения данных. Cassandra также не обладает гибкостью запросов, характерной для реляционных баз данных. Она не поддерживает объединения и может выполнять запросы только к одной таблице. Поэтому, при рассмотрении того, как моделировать данные в Cassandra, в первую очередь необходимо учитывать паттерны доступа к данным вашего приложения. Важно понимать, какие данные необходимы в каждой таблице, чтобы можно было денормализовать (продублировать) данные по таблицам по мере необходимости. Основные области, которые следует учитывать:
- Ключ партиционирования (Partition Key) - какие значения определяют раздел, в котором хранятся данные.
- Размер раздела (Partition Size) - насколько велик раздел в самом крайнем случае, имеют ли разделы возможность расти бесконечно и т.д.
- Кластерный ключ (Clustering Key) - как должны быть отсортированы данные (если вообще должны).
- Денормализация данных (Data Denormalization) - нужно ли денормализовывать определенные данные по таблицам для поддержки запросов приложения.
Чтобы лучше усвоить это, полезно рассмотреть некоторые примеры.
Пример: Сообщения Discord
Один из лучших способов научиться пользоваться инструментом вроде Cassandra - это изучить реальный пример, подобный Discord. Команда Discord поделилась хорошей выжимкой своего опыта использования Cassandra для хранения сообщений, и это хороший образец того, как можно подойти к хранению сообщений для приложений чатов в целом.
Каналы Discord могут быть весьма оживленными с большим количеством сообщений. Пользователи обычно запрашивают недавние данные, поскольку канал представляет собой большой групповой чат. Пользователи могут запрашивать свежие данные и прокручивать ленту немного назад, поэтому имеет смысл сортировать данные в обратном хронологическом порядке.
Для удовлетворения вышеуказанных потребностей Discord изначально решил создать таблицу сообщений со следующей схемой:
CREATE TABLE messages (
channel_id bigint,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY (channel_id, message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);Вы можете задаться вопросом, почему в качестве кластерного ключа используется
message_id, а не временная метка типа created_at? Discord выбрал
использование Snowflake
ID для
сообщений, чтобы исключить вероятность конфликтов первичных ключей в Cassandra.
Snowflake ID - это, по сути, хронометрически сортируемый UUID. Это
предпочтительнее, чем created_at, потому что коллизия Snowflake ID невозможна
(это UUID), тогда как временная метка, даже с точностью до миллисекунд, имеет
вероятность коллизии.
Приведенная выше схема позволяет Cassandra обрабатывать сообщения для канала
через единый раздел. Ключ партиционирования (channel_id) гарантирует, что
только один раздел отвечает за обработку запроса, предотвращая необходимость
выполнения запроса "разбросать-собрать" (scatter-gather) по нескольким узлам для
получения сообщений канала, что могло бы занимать много времени и ресурсов.
Однако приведенная выше схема полностью не удовлетворяла потребности Discord. Некоторые каналы Discord могут содержать очень много сообщений. Используя данную схему, команда Discord заметила, что Cassandra испытывает трудности с обработкой больших разделов, соответствующих активным каналам Discord. Большие разделы в Cassandra обычно сталкиваются с проблемами производительности, и именно это наблюдали разработчики Discord. Кроме того, каналы Discord могут постоянно увеличиваться в размере вместе с активностью пользователей и рано или поздно столкнуться с проблемами производительности, если будут существовать достаточно долго. Поэтому требовалось внести изменения в схему.
Чтобы решить проблему больших разделов, Discord ввела концепцию корзины bucket
и добавила ее в состав ключа партиционирования. Каждая корзина представляла
собой данные за 10 дней, определяемые фиксированным окном, привязанным к
собственной эпохе Discord DISCORD_EPOCH - 1 января 2015 года. Даже самые
активные каналы Discord могли уместить все свои сообщения за 10-дневный период в
одном разделе Cassandra. Это также решило проблему монотонного роста размеров
разделов; со временем создавался новый раздел, так как появлялась новая корзина.
Переработанная схема выглядит следующим образом:
CREATE TABLE messages (
channel_id bigint,
bucket int,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);Стоит отметить, что Discord использовал паттерны доступа к своим каналам для разработки схемы, что является отличным примером проектирования данных исходя из запросов к этим данным. Их выбор первичного ключа, включая ключ партиционирования и кластерный ключ, тесно связан с тем, как данные извлекаются для их приложения. Наконец, при разработке схемы пришлось задуматься о размерах разделов. Все эти факторы играют роль в создании хорошей схемы Cassandra для проектирования системы.
Пример: Ticketmaster
Рассмотрим еще один пример использования Cassandra: интерфейс просмотра билетов (Ticketmaster UI). Это тот самый интерфейс, который отображает доступные места на площадке мероприятия и позволяет пользователю выбрать места, а затем перейти к оформлению заказа и оплате.
Ticketmaster UI не требует строгой согласованности. Доступность билетов на мероприятие меняется даже тогда, когда пользователь просматривает сайт. Если место выбрано и попытка покупки начата, система может проверить базу данных (со строгой согласованностью), чтобы определить, действительно ли место доступно. Кроме того, большинство пользователей будут только просматривать билеты и лишь небольшая часть перейдет непосредственно к процессу оформления заказа.
Этот пример мы хотим сделать простым и сосредоточиться исключительно на модели данных, поэтому мы опустили сложности, возникающие при организации невероятно популярных мероприятий ("Проблема Тейлор Свифт").
Рассматривая, как смоделировать наши данные для поддержки Ticketmaster UI, мы можем думать о каждом месте как об отдельном билете. Анализируя паттерны доступа в нашей системе, мы обнаруживаем, что пользователи запрашивают данные по одному событию за раз и хотят видеть общее количество доступных мест, а также сами места. Порядок представления мест пользователям неважен, так как у них будет карта площадки мероприятия, которая определяет, как они видят доступность мест. Первая итерация нашей схемы может выглядеть следующим образом:
CREATE TABLE tickets (
event_id bigint,
seat_id bigint,
price bigint,
-- поле seat_id добавляется как кластерный ключ для обеспечения уникальности
-- первичного ключа; порядок не важен для паттернов доступа приложения
PRIMARY KEY (event_id, seat_id)
);Используя приведенную выше схему, приложение может запрашивать данные из
единственного раздела, учитывая, что ключ партиционирования включает поле
event_id. Приложение может запросить один раздел для получения ценовой
информации о мероприятии, общих сведений о доступности билетов и т.д.
Тем не менее, эта схема имеет проблемы. Для мероприятий с более чем 10 000 билетов база данных вынуждена выполнять работу по агрегации информации на основе запроса пользователя (например, общее количество билетов по секциям с ценами). Такая работа может выполняться часто для популярных мероприятий, где пользователи регулярно заходят в Ticketmaster UI. Как мы можем решить эти проблемы?
Подсказка относительно того, как мы можем улучшить нашу схему, кроется во взаимодействия пользователя с Ticketmaster UI. Рассмотрим взаимодействие пользователя при просмотре билетов. Они видят карту площадки с секциями. У каждой секции может быть всплывающее окно с общей информацией о наличии билетов и ценах в этой секции.
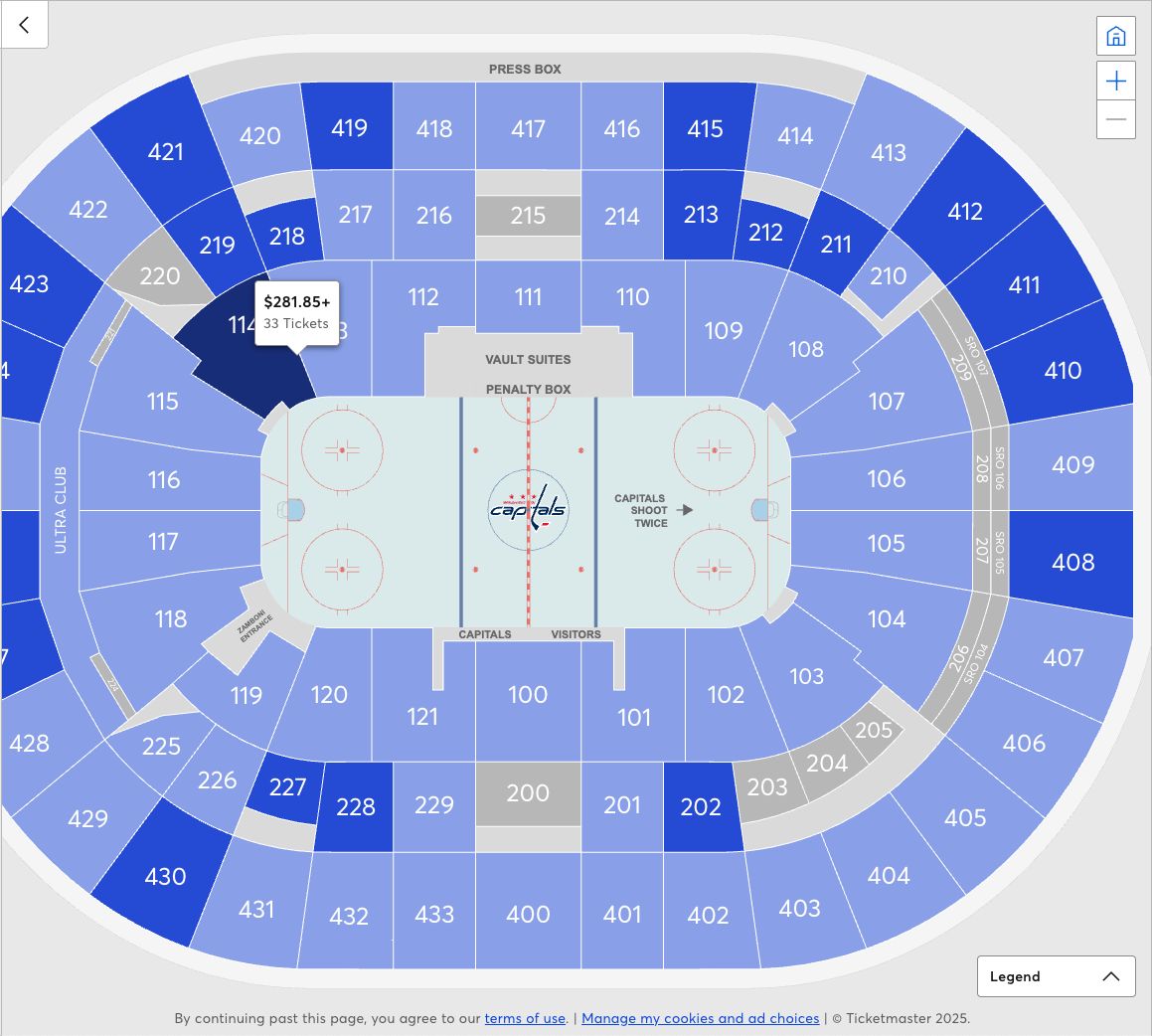
Если пользователь выбирает интересующую его секцию, Ticketmaster UI затем показывает отдельные места и информацию о билетах.
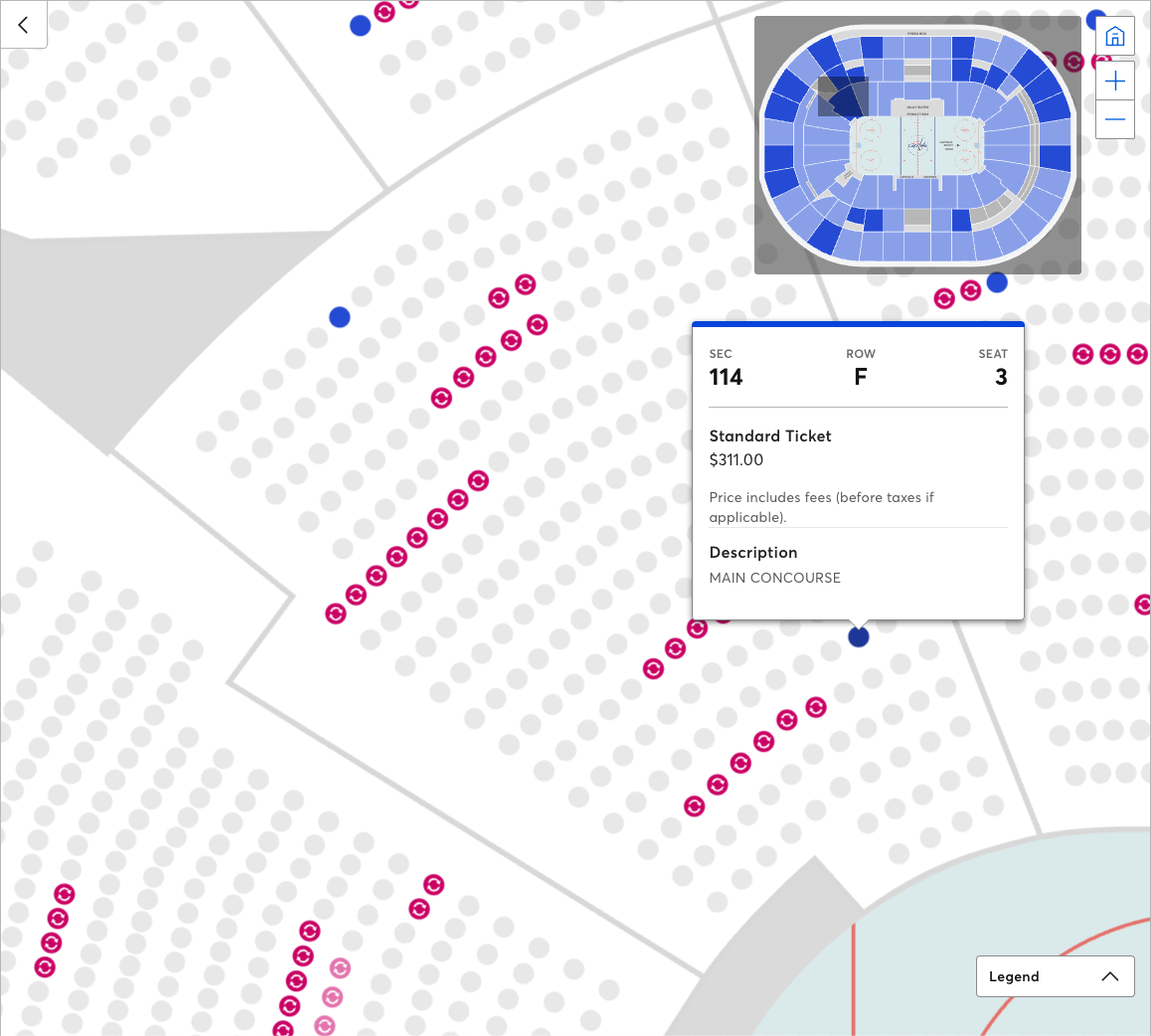
Данный паттерн взаимодействия открывает нам возможность добавить понятие
section_id в нашу таблицу билетов и включить section_id в качестве части
ключа партиционирования. Это означает, что таблица билетов теперь обрабатывает
запрос на просмотр отдельных билетов на места для заданной секции. Новая схема
выглядит следующим образом:
CREATE TABLE tickets (
event_id bigint,
section_id bigint,
seat_id bigint,
price bigint,
PRIMARY KEY ((event_id, section_id), seat_id)
);Представленная выше схема является улучшением оригинальной версии. Эта схема распределяет данные по нескольким узлам кластера Cassandra, так как каждая секция находится в отдельном разделе. Это также означает, что каждый раздел отвечает за обслуживание меньшего объема данных, поскольку количество билетов в разделе меньше. Наконец, данная схема лучше соответствует требованиям к данным и паттернам доступа Ticketmaster UI.
Возможно, у вас возникнет вопрос:
Как теперь показать данные о билетах для всего мероприятия?
Чтобы сделать интерфейс, показывающий все секции и общую информацию о
доступности билетов и ценах, мы можем рассмотреть создание отдельной таблицы
event_sections.
CREATE TABLE event_sections (
event_id bigint,
section_id bigint,
num_tickets bigint,
price_floor bigint,
-- поле section_id добавляется как кластерный ключ для обеспечения уникальности
-- первичного ключа; порядок не важен для паттернов доступа приложения
PRIMARY KEY (event_id, section_id)
);Эта таблица иллюстрирует идею "денормализации" данных в Cassandra. Вместо того чтобы заставлять нашу базу данных агрегировать данные из таблицы или запрашивать несколько таблиц / разделов для обслуживания приложения, предпочтительно денормализовать такую информацию, как количество билетов и минимальная цена в секции, чтобы сделать доступ к приложению эффективным. Кроме того, статистика по секциям, которую запрашивают, не обязательно должна быть предельно точной - допускается конечная согласованность.
Данная таблица партиционируется по полю event_id. Cassandra будет стараться
получить множество секций одним запросом, однако у каждого мероприятия небольшое
количество секций (обычно меньше 100), и этот запрос будет обслуживаться одним
разделом. Это значит, что Cassandra сможет эффективно запрашивать данные для
отображения верхнего уровня вида площадки.
Этот пример хорошо иллюстрирует, каким образом паттерны доступа приложения и пользовательский интерфейс оказывают значительное влияние на то, как данные моделируются в Cassandra.
Продвинутые возможности
Помимо основных сценариев использования Cassandra, стоит ознакомиться с некоторыми продвинутыми функциями, имеющимися в вашем распоряжении. Ниже приведен короткий список некоторых из ключевых возможностей.
-
Индексы, подключенные к хранилищу (Storage Attached Indexes, SAI) - это сравнительно новая функция в Cassandra, позволяющая создавать глобальные вторичные индексы по столбцам. Эти индексы позволяют гибко получать данные с производительностью несколько хуже традиционной выборки по ключу партиционирования, но все же этого достаточной для большинства задач. Использование SAIs избавляет от избыточной денормализации данных, если существуют редко используемые паттерны запросов. Подробнее о SAIs можно узнать здесь.
-
Материализованные представления (Materialized Views) - позволяют пользователям настраивать Cassandra таким образом, чтобы автоматически материализовались таблицы на основе исходной таблицы. Материализованные представления похожи на обычные SQL-представления, за исключением того, что они фактически создают новую физическую таблицу, отсюда и название. Это удобно, так как вам больше не придется вручную заниматься денормализацией данных. Когда изменяется исходная таблица, Cassandra сама обновляет соответствующие материализованные представления, снижая сложность вашего приложения.
-
Индексация поиска (Search Indexing) - Cassandra может быть интегрирована с распределенными системами поиска, такими как Elasticsearch или Apache Solr, через разные плагины. Один из примеров - индекс Stratio Lucene. Подробнее о нем можно узнать здесь.
Cassandra на собеседовании
Когда стоит использовать
Cassandra отлично подходит для систем, где приоритет отдается доступности над согласованностью и существует высокая потребность в масштабируемости. Cassandra способна быстро записывать и считывать большие объемы данных, особенно хорошо проявляя себя в системах с высокой пропускной способностью записи благодаря оптимизированному слою хранения, основанному на индексации LSM-tree. Кроме того, архитектура семейства столбцов (wide-column) Cassandra делает ее отличным вариантом для баз данных с гибкими схемами или схемами, включающими большое число разреженных столбцов. Наконец, Cassandra эффективна, когда у вашей системы есть четко определенные паттерны доступа, вокруг которых можно построить схему.
Понимание ограничений
Cassandra подходит не для всех типов систем. Cassandra плохо подходит для систем, где предпочтение отдается строгой согласованности, так как она ориентируется преимущественно на доступность. Cassandra также не рекомендуется для систем, которым требуются сложные запросы, такие как объединение нескольких таблиц (multi-table JOINs), произвольные агрегации данных и т.д.
Заключение
Теперь вы понимаете почему Cassandra является отличным инструментом для распределенных систем. При ее использовании важно применять подход к моделированию данных, ориентированный на запросы, чтобы максимизировать преимущества Cassandra в плане скорости записи и масштабируемости. При погружении в дизайн системы знание внутренних механизмов Cassandra играет ключевую роль в правильном ее использовании.